For the umpteenth time, one of the extra fun parts of having three intermittent decades of experience in computer programming, both web development related and not, is that you have a near-instinctive idea of how computer logic works. You start out the tech boot camp knowing that you need to make sure the conditions are true, that you haven’t left a loop running, that you aren’t sending the compiler or engine looking for a variable that doesn’t exist. That solves a lot of problems before they can come up. Unfortunately, it’s still not proof against the really–
— I don’t want to call them ‘stupid’ problems, because they’re not. I’ll call them Sub-Optimal Coding Conditions problems. I shouldn’t have tried this on five hours of broken sleep. —
the Sub-Optimal Coding Conditions problems. The SOCC problems. The ones you make when you’re tired, or you forgot to eat lunch (and breakfast), or you’ve been looking at the same code for two and a half hours without a break. I will continually bang this drum, and occasionally have it bounced off my head: you will write your best code when you’re hydrated, fed, and rested. And have recently thought about something that is not code.
Today I was working on a project for boot camp, never mind what it does for now but the setup to the joke is I had two objects, Item and Source. They were tied through the join table ItemSources. I had a form for new Items and a part of that form was you could pick a Source for that item from a list of checkboxes, or pick multiple Sources, or you could create a new Source by name. So let’s go through the code piece by piece, shall we? Can you figure out where the SOCC problem arose before I could? Because it took me a good hour or so.
c
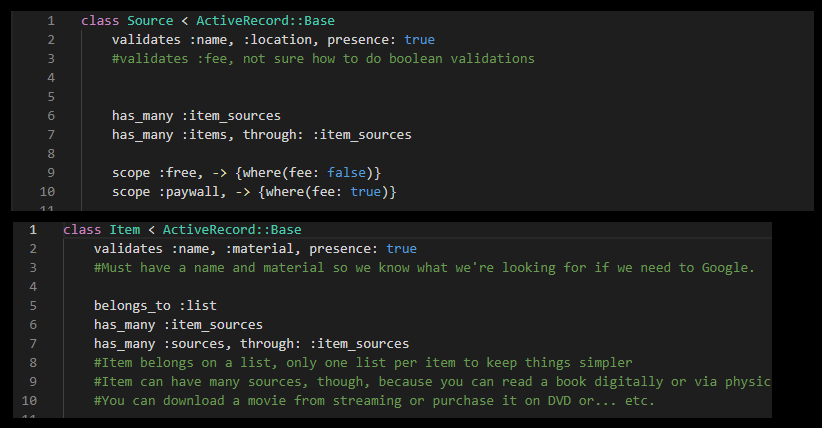
Everything looks good, right? We’ve got validations, relationships. An Item belongs to a List, and then the aforementioned relationship to Sources. We also had the sources-attributes writer method, where we take the attributes fed in through the form and create a new Source object if we can’t find one by that name already. I went through a couple variations on this code trying to figure out where I’d gone wrong, but this is probably the cleanest version.
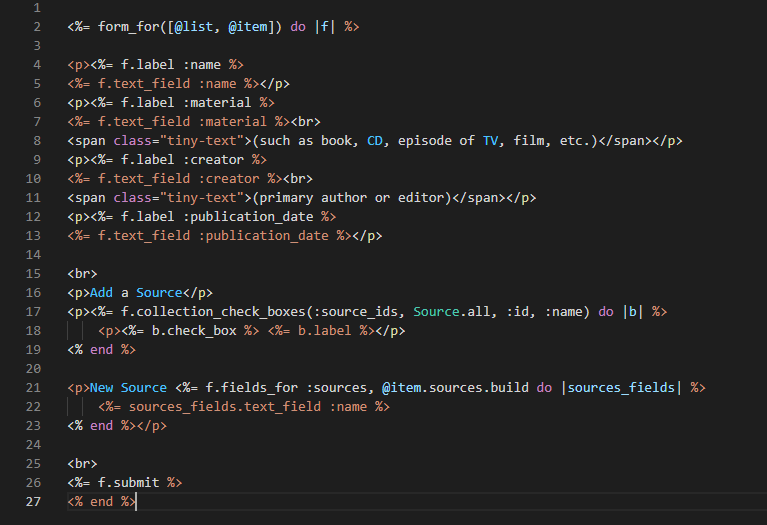
So here we’ve got the Item form, and again, everything looks good, right? Well, not entirely, it took me a couple rounds of coding in here to remember that a fields_for method exists, but I did get there eventually and thought, hah, that solves my problem! It did not. I went back and I dug out of an earlier lab the notes where I’d coded this in bare HTML rather than erb language, hoping that would help for some reason. It did not.
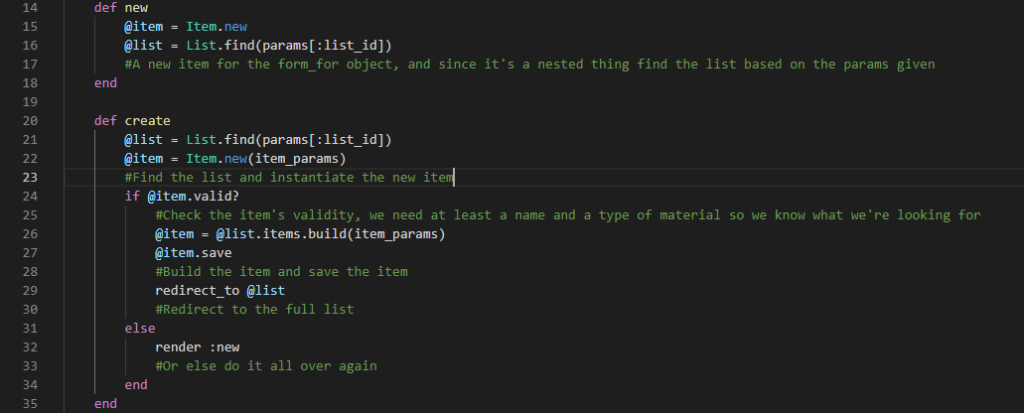
Was it in the controller? I didn’t see how it could be, the controller code was already pretty clean and I knew what each part did, I didn’t see a place that I’d missed a step, but I went over it anyway. Twice. Didn’t help. At this point I was getting irritated and nervous, and this is definitely when I started thinking I should have put a pause on the code till tomorrow, but no. Because sometimes I know better, and I push anyway.
I used the tried and true method of taking each step of the code as slowly as I could make it. I put in a byebug interrupt to pause it after the user, that is to say me, had fed data into the form to see what I was working with. I went over each step of the program in the Rails console carrying it through to the next step manually, line by line. By now I was in the Item model code, going through the source_attributes writer method and discovered that it wasn’t actually writing the new Source object. Okay. But why wasn’t it writing the new Source object?
This is the part where, if I’m being honest, it was only luck that made me think of the actual problem instead of going in circles for another hour and then shamefacedly taking myself to someone else to look over it. I didn’t type anything, I went over in my head the steps of creating a new Source object. What were the necessary and relevant items needed to create a Source object? Well, it needed a name, the rest of it could be added in edits, and I went over to the Source model to see what else was going on in here.
And there it was staring me in the face. validates :name, :location, presence: true. The only problem here is that the fields_for method only took in an argument for a name, no location. So the params fed into creating the new Source object would fail validation, the new object wouldn’t be created, and thus my problem. I spent an entire hour figuring out that it was nine freaking characters ruining my whole process and driving me up a wall and back down again. This is why we don’t code tired, friends. It doesn’t entirely eliminate these kinds of errors to make sure you’re working rested, fed, and watered, but it does help cut down on them.
Eventually I’ll have enough practice in Rails to put that validation back in, but for now taking it out was the easier solution to get the project finished and turned in. I did add it to the stretch goals in the project notes, as well as a brief reminder to myself in the dev log to check your validations if you’re wondering why an object won’t write. It’s useful, I find, to have a mental or physical list of first things to check and make sure you haven’t forgotten or miswritten. Double checking to make sure I included a save method where it should go has saved me a lot of grief, I tell you what. And now I can add checking my validations to the list.